Optimize query performance using OpenSearch indexing
Introduced 2.11
Query performance can be slow when using external data sources for reasons such as network latency, data transformation, and data volume. You can optimize your query performance by using OpenSearch indexes, such as a skipping index or a covering index. A skipping index uses skip acceleration methods, such as partition, minimum and maximum values, and value sets, to ingest and create compact aggregate data structures. This makes them an economical option for direct querying scenarios. A covering index ingests all or some of the data from the source into OpenSearch and makes it possible to use all OpenSearch Dashboards and plugin functionality. See the Flint Index Reference Manual for comprehensive guidance on this feature’s indexing process.
Data sources use case: Accelerate performance
To get started with the Accelerate performance use case available in Data sources, follow these steps:
- Go to OpenSearch Dashboards > Query Workbench and select your Amazon S3 data source from the Data sources dropdown menu in the upper-left corner.
-
From the left-side navigation menu, select a database. An example using the
http_logsdatabase is shown in the following image.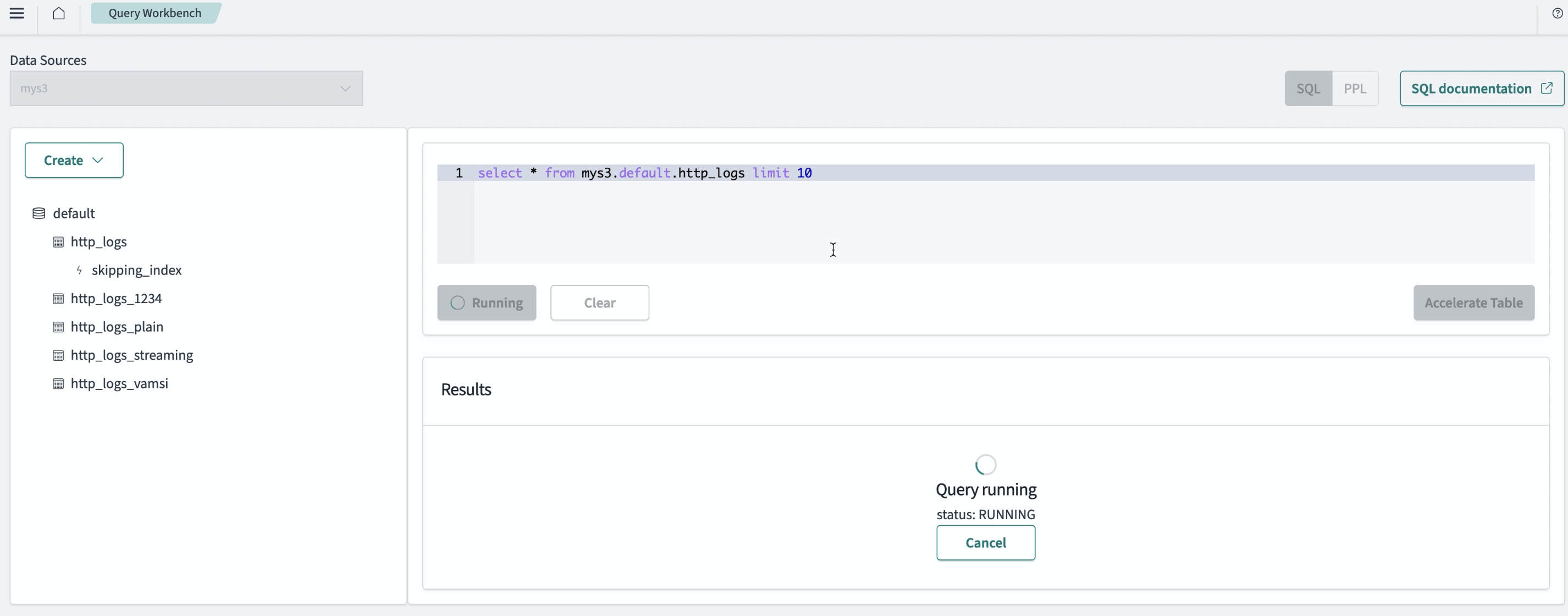
- View the results in the table and confirm that you have the desired data.
- Create an OpenSearch index by following these steps:
- Select the Accelerate data button. A pop-up window appears. An example is shown in the following image.
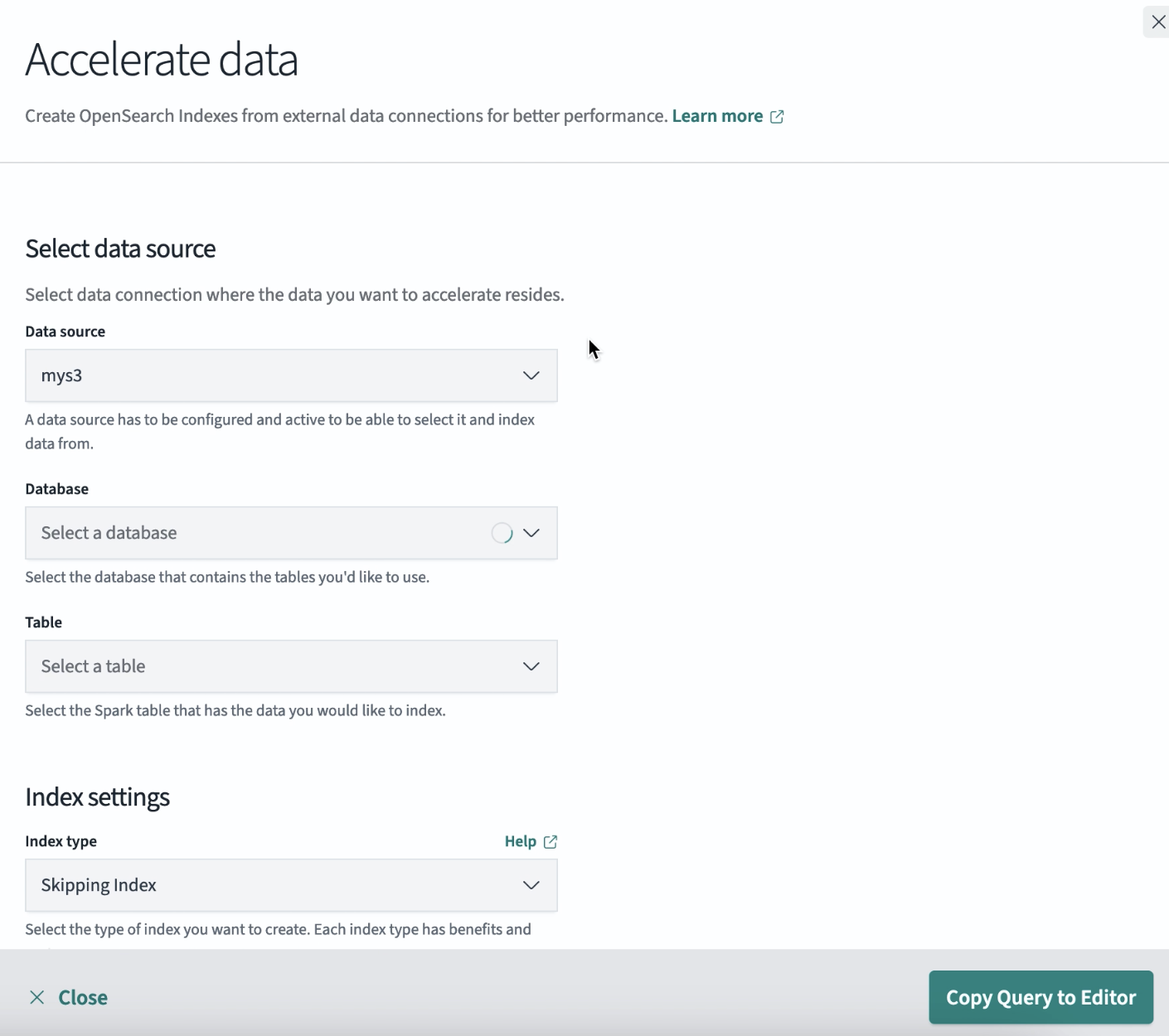
- Enter your details in Select data fields. In the Database field, select the desired acceleration index: Skipping index or Covering index. A skipping index uses skip acceleration methods, such as partition, min/max, and value sets, to ingest data using compact aggregate data structures. This makes them an economical option for direct querying scenarios. A covering index ingests all or some of the data from the source into OpenSearch and makes it possible to use all OpenSearch Dashboards and plugin functionality.
-
Under Index settings, enter the information for your acceleration index. For information about naming, select Help. Note that an Amazon S3 table can only have one skipping index at a time. An example is shown in the following image.
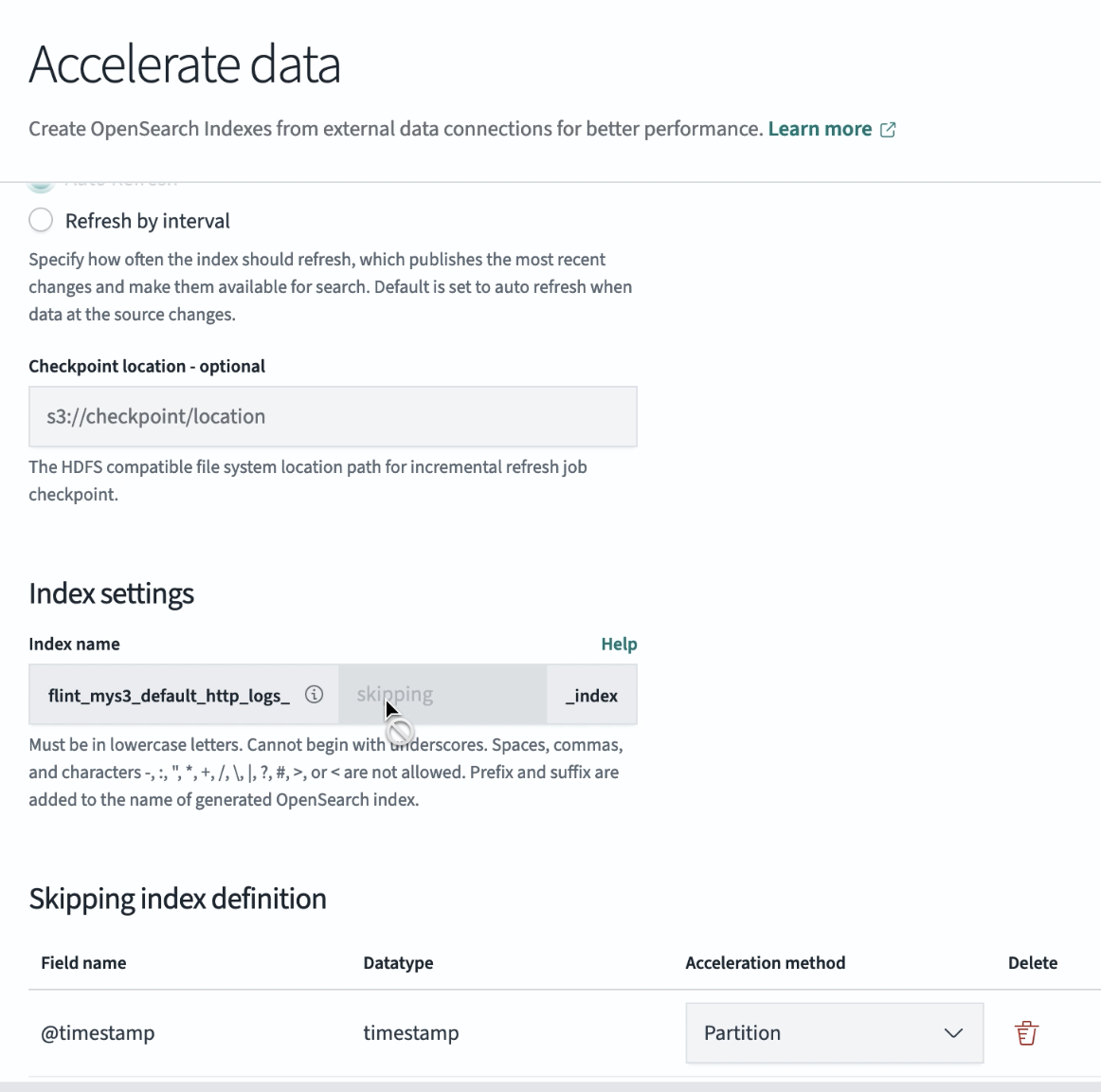
Define skipping index settings
-
Under Skipping index definition, select the Add fields button to define the skipping index acceleration method and choose the fields you want to add. An example is shown in the following image.
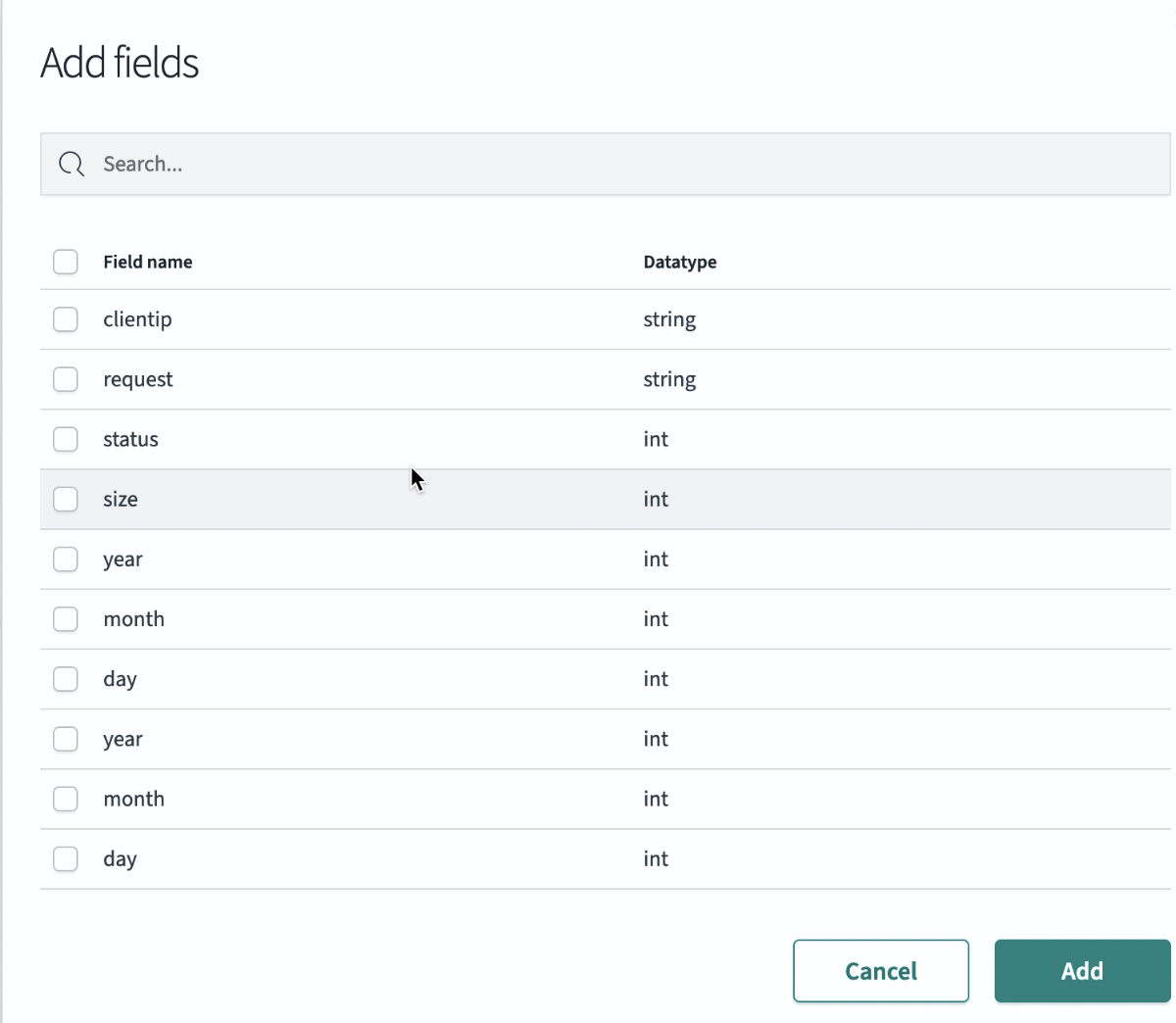
- Select the Copy Query to Editor button to apply your skipping index settings.
-
View the skipping index query details in the table pane and then select the Run button. Your index is added to the left-side navigation menu containing the list of your databases. An example is shown in the following image.

Define covering index settings
-
Under Index settings, enter a valid index name. Note that each Amazon S3 table can have multiple covering indexes. An example is shown in the following image.
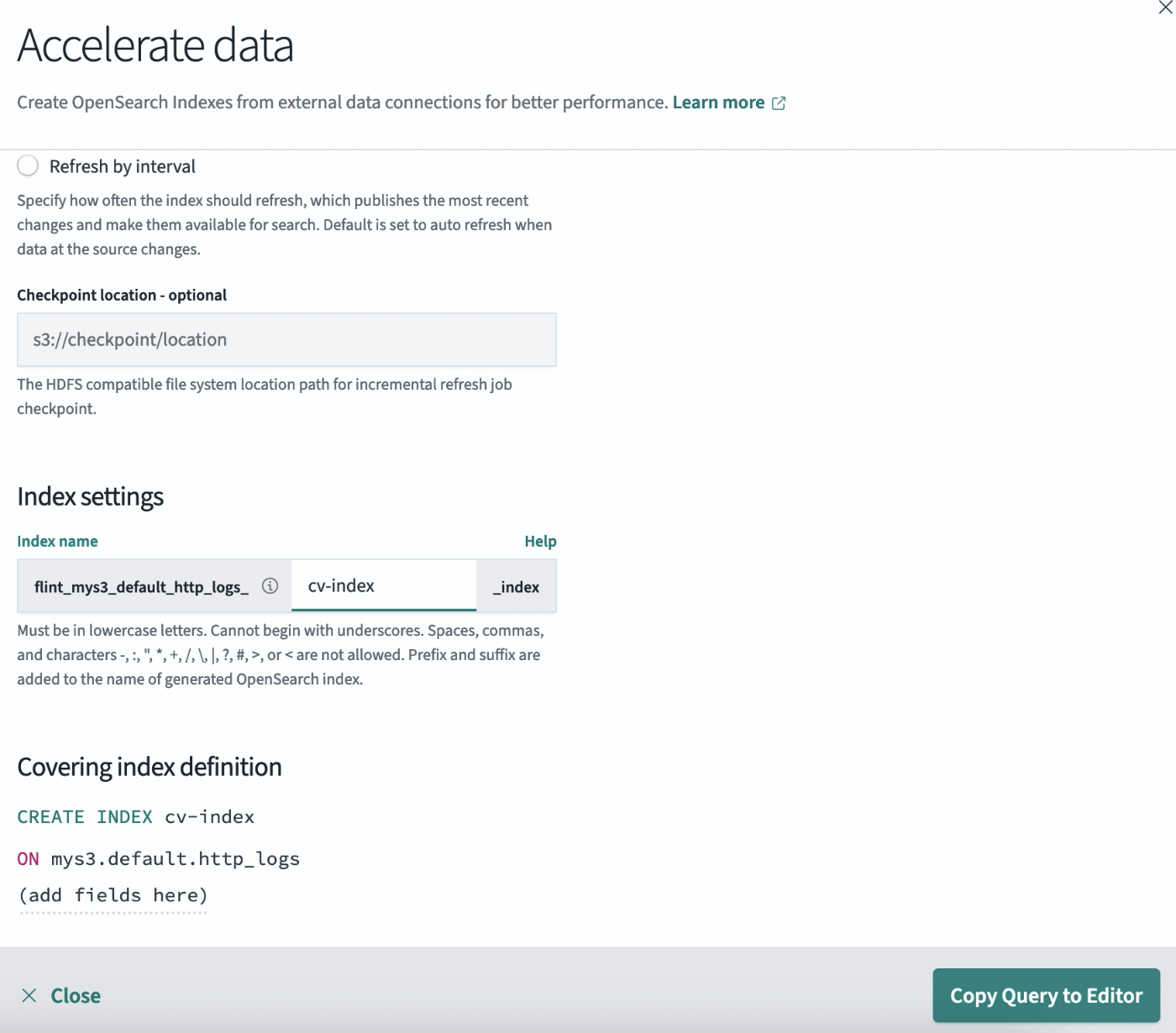
-
Once you have added the index name, define the covering index fields by selecting
(add fields here)under Covering index definition. An example is shown in the following image.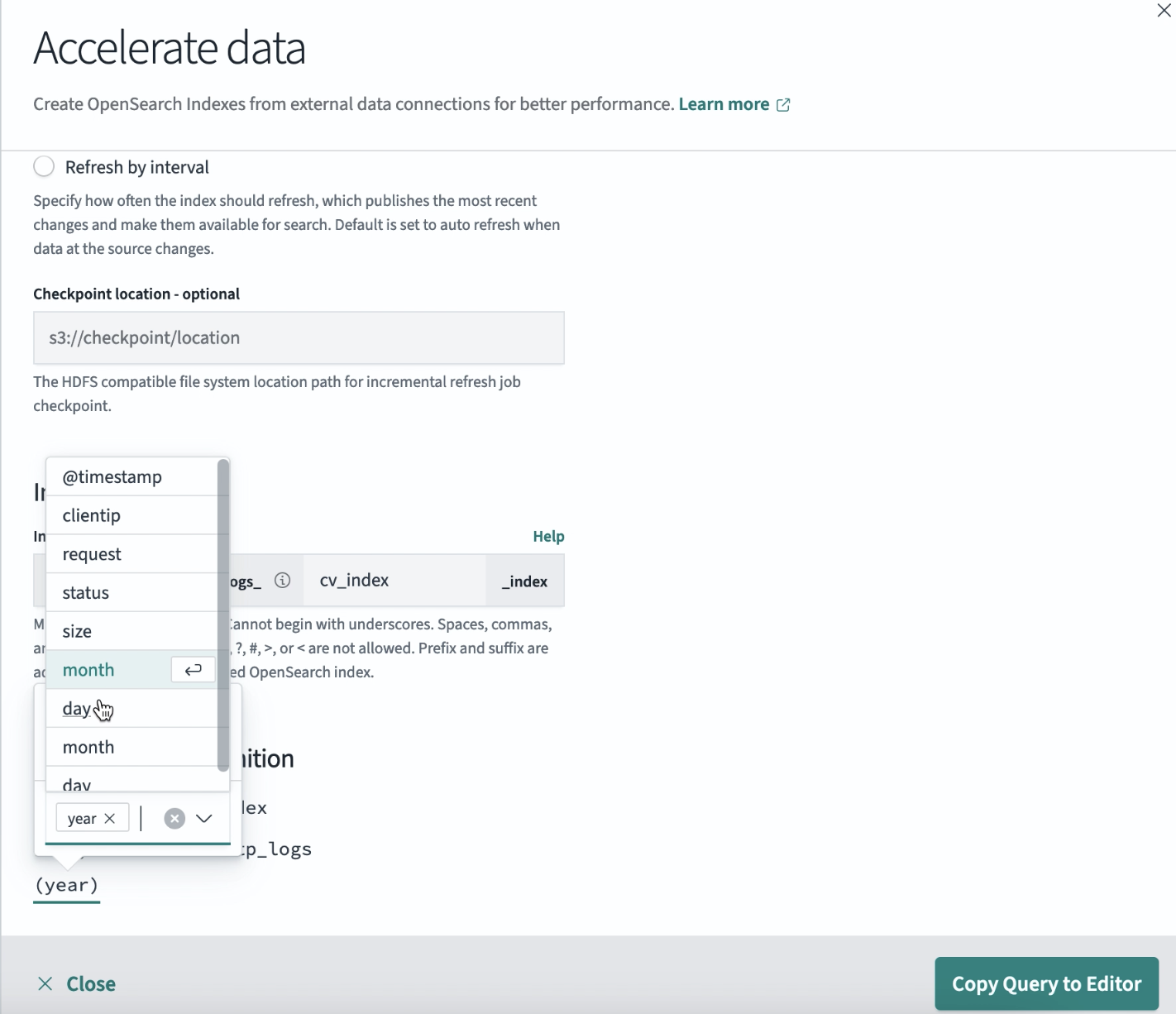
- Select the Copy Query to Editor button to apply your covering index settings.
-
View the covering index query details in the table pane and then select the Run button. Your index is added to the left-side navigation menu containing the list of your databases. An example UI is shown in the following image.
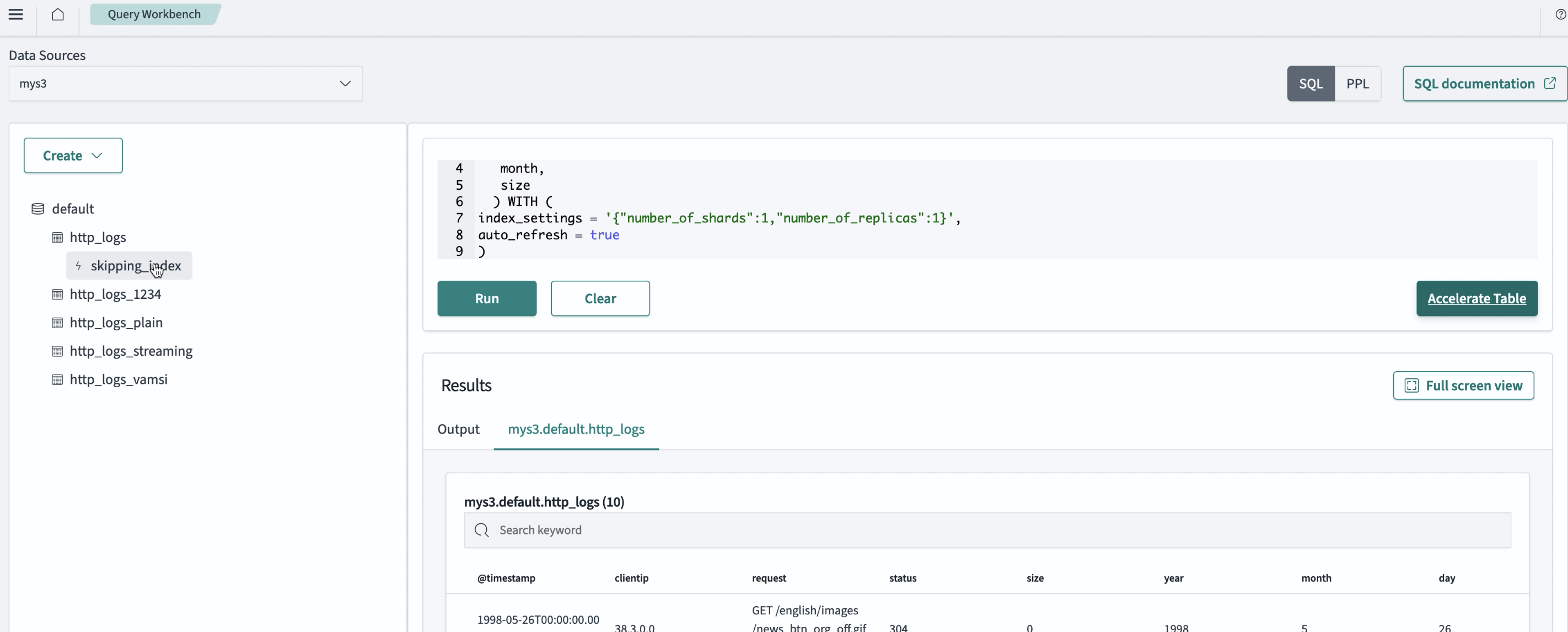
Limitations
This feature is still under development, so there are some limitations. For real-time updates, see the developer documentation on GitHub.